Genome assembly from sequencing reads
Overview
QuestionsObjectives
Requirements
Time estimation:
Introduction
The CPT conducts routine phage genome sequencing runs using Illumina sequencing for our research. In this tutorial users will learn how to process the Illumina short reads sequences and assemble phage genomes. This starts from retrieving the raw read data stored in the CPT share data libraries into the CPT Galaxy, trimming those reads, and proceeds through assembly with SPAdes and initial analysis of the contig.
Agenda
Import Sequencing Data into a New History in Galaxy
The CPT researcher performing the sequencing runs will upload the sequence reads data from Illumina BaseSpace into a shared data library in Galaxy. The researcher performing the genome assembly will need to retrieve the sequence reads data from the shared data library into a new Galaxy history before conducting assembly.
- Under the “Shared Data” drop-down menu at the top of the Galaxy home page, click on “Data Libraries”.
Click on “CPT Sequencing.” On that page, the different sequencing runs are sorted by Year-Month.
Select the folder that contains your sequence data, identify which index contains the R1 and R2 reads (the forward and reverse reads, respectively) you need to assemble. Your data file should be a .fastq, fastqsanger, or .fastqsolexa/equivalent.
Impot your sequence reads data into a history. This can be done by clicking the “to History” button at the top of the current index. You have the option of either transfering to an existing history or creating a new history. If there are multiple samples across multiple indexes, it is a good practice to make sure each index gets its own history.
- Once the data has been imported and it is ready to assemble, return to the Galaxy Homepage where all the tools can be accessed.
Running the Quality Control Report and Trimming the Reads
To learn about the quality control analysis (FASTQC), read the FastQC Manual and watch this quick video that explains each analysis module.
FastQC to Trimming
- Using the Search bar in the Tools column on the left side of the Galaxy interface, search “FastQC.” Find the FastQC Read Quality reports result.
- Run the FastQC tool (use this tool link if you are TAMU internal user) on both R1 and R2 reads separately. This tool results in two output entries in the history.
Once the tool has run, click the eye symbol on the resulting dataset under the History column to view the Webpage generated (not the RawData output).
Identify Trimming Parameters by observing two modules, beginning with the Per Base Sequence Content Module. The lines should be parallel and fairly consistent throughout. Take note of the base # where the lines diverge too much, as these will be the points to trim at. Below is an example in which one might trim after base 245.
- The second module to analyze is the Per base Sequence Quality Module. Ideally, the quality score for reads that are trimmed will remain high (at least above 20). To better understand what is and isn’t a good quality score, watch this short video. Below is an example of a good report where the first 20 bases and the bases after 250 might be trimmed.
- Using the Galaxy Trim sequences tool (use this tool link if you are TAMU internal user), set the base parameters, and execute for both R1 and R2.
Note that…
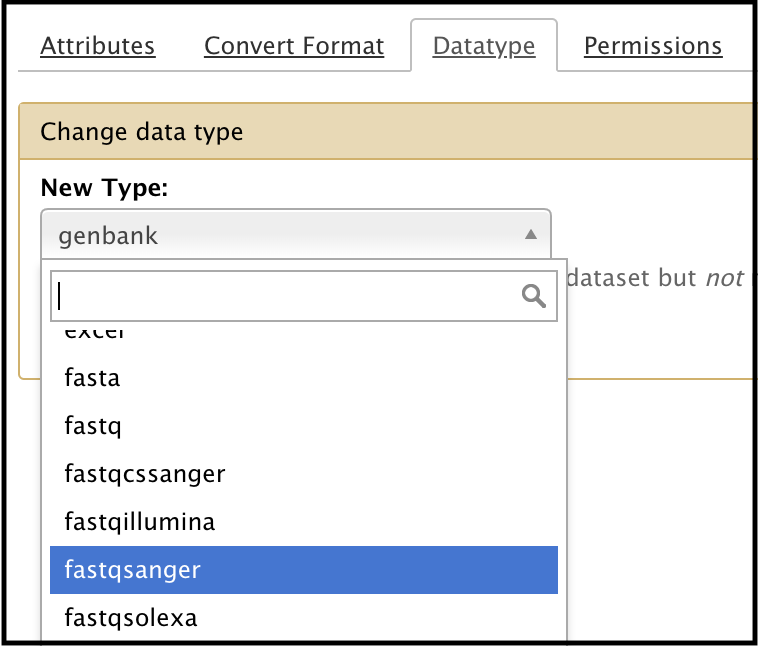
The Trim sequences tool cannot use a .fastq file as input. If the data is in the .fastq format, it can be converted into the appropriate format in Galaxy. Under the history entry containing the .fastq file, find the dataset for the .fastq file, and click the icon (Edit Attributes). When the attributes appear in the center panel, select “Datatype” at the top. Use the drop-down menu to select .fastqsanger (or equivalent), then click save.






Assemble the Contig Using SPAdes
Search for SPAdes in the search bar underneath the Tools column on the left side of the Galaxy interface.

Selecting the Galaxy spades tool (use this tool link if you are TAMU internal user) and adjust the following parameters:
- K-mers
- All values must be odd, less than 128, listed in ascending order, and smaller than the read length.
- Smaller values = more stringent (less contigs assembled, more accurate contigs)
- Larger values = less stringent (more possible contigs, possible error in assembly)
-
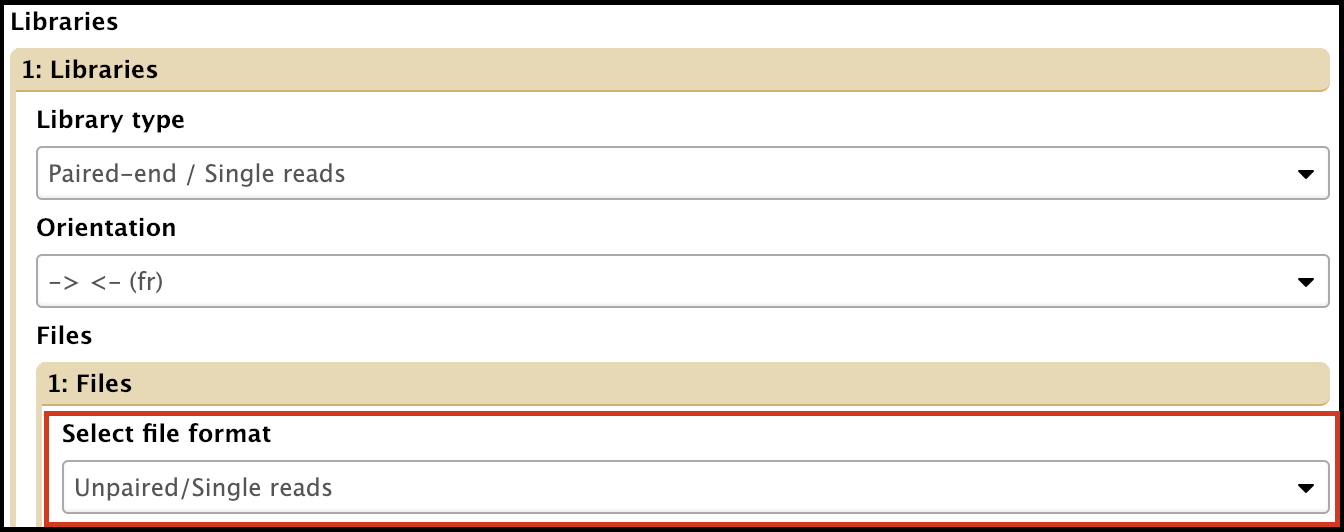
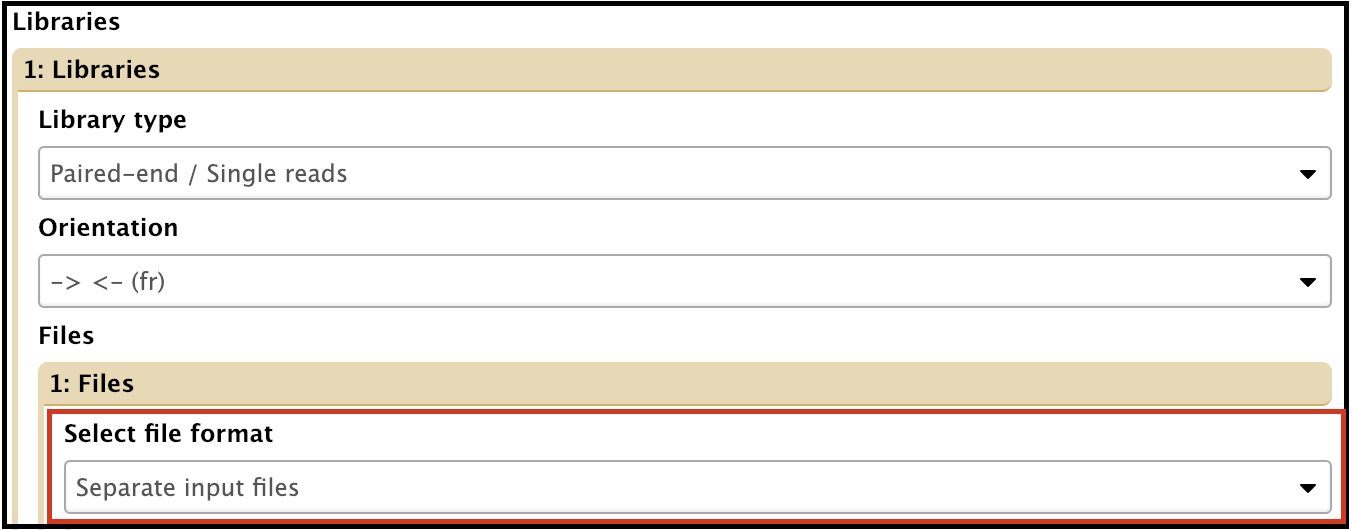
Library type is Paired-end/Single reads
- File format: can use one or both of the reads sets
Unpaired/Single reads assembly can be run using trimmed forward (R1) or reverse (R2) reads.
Separate input files assembly uses both forward and reverse reads and it usually gives the best output, assuming both reads data show good QC reports.
Note that…
Single SPAdes run using one type of setting does not always yield the best output. It is recommended that muiltiple instances of spades assembly using different settings (different choices for K-mer values and data inputs) are carried out to compare the results.
Once all of the parameters have been set, execute the spades tool by clicking the Execute button at the bottom of the tool. This could take up to a few hours; however, multiple spades assemblies can be run at once.
After the tools have finished running, there will be 5 outputs from each SPAdes run in the history column.

The contigs from each SPAdes iteration can be organized based on size by running the Sort tool. (use this tool link if you are TAMU internal user)


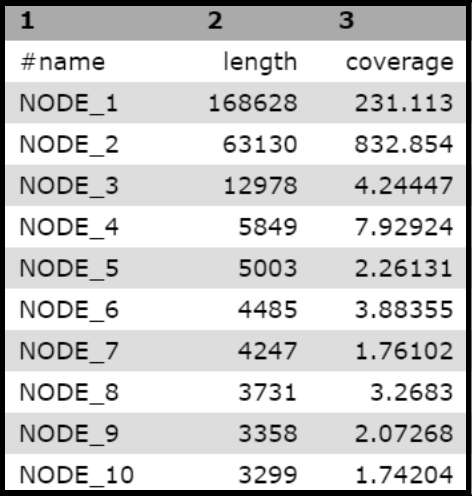
Choosing “Spades scaffold stats” as the Sort Dataset option and “Column: 2” for on column will yield an outcome that looks something like this:
Note that…
“SPAdes scaffold stats” and “SPAdes contig stats” should have very similar sorting results, though there can be a few differences between the two. If there is trouble finding a contig using one dataset, try checking the other dataset.
What to Look For
Most of the time, there is a general idea of the expected size of the genome that has been sequenced, based on restriction digest or Pulse Field Gel Electrophoresis results. Look for contigs in that size range.
Look for contigs with a coverage much higher than the rest of the list. Often contigs with much higher coverage than the rest of the list represent the desired sequence.
Look for contigs that are the same size in the assembly that came out of using R1 alone, R2 alone, and both R1 and R2 together
If unsure, extract a few candidate nodes and try BLAST them as outlined below.
In the end, the contig can only definitely be assigned to a specific sample (and shown that it is complete) after a confirmation PCR is attempted, and the genome is closed using PCR/Sanger sequencing. Tutorial on Genome closure and re-opening.
To extract the contig of interest from the assemled contig pool, run the Fasta Extract Sequence tool (use this tool link if you are TAMU internal user) and define the contig (node) of interest; this pulls out the FASTA file associated with the specific node.
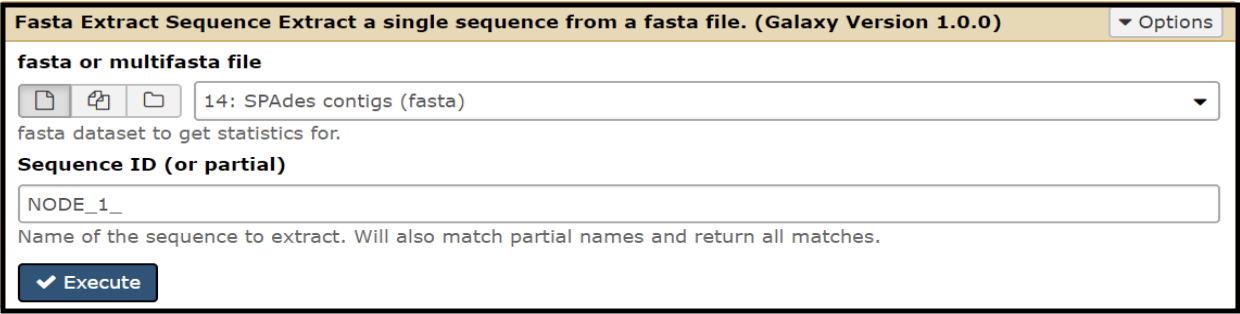
Choose “SPAdes contigs (fasta)” as the data file. Under “Sequence ID (or partial),” type in the node you want to extract. Be sure to type in an underscore after the node number! Example: NODE_21_. If the underscore is left out, it will extract the wrong node
Preliminary analysis
Now, BLAST that contig sequence! The will help identify which genome from the index this sequence is most likely associated with (ideally, do PCR confirmations to be 100% sure).
- Use BLASTn + megablast, as it will yield the most closely related organisms. For a broader net, choose a different algorithm.
- Doing the analysis on the home BLAST website will give a quick answer, but this is not a result that can be saved. To save a record for later reference, doing BLAST in Galaxy is recommended.
- Doing the BLAST in Galaxy will yield a permanent link that can be stored for reference. Choose the output as BLAST html or XML. Later, the blast2html tool tool (use this link for TAMU internal user) must be used to convert XML to html. After the result is ready, right-click on the eye icon and choose “open in a new tab.” The hyperlink can be copied and subsequently shared with other researchers or pasted into a tracking sheet where confirmation and closure information is compiled.
Extracted sequences appear in the history as such:

- First, click on the pencil
icon to bring upon the attributes of that dataset. Rename the dataset by editing the “Name” section of the attributes, and then select “Save.” Example name: NODE_X:RawName (“raw” because this is the raw, unclosed contig).
- Next, rename it using the “Fasta Sequence Renamer” tool. (use this tool link if you are TAMU internal user). Do NOT put “raw” in this name, because this is the identifier that Galaxy will use to identify the contig, no matter how it is edited. This changes the header in the FASTA file on the first line after the >


Another preliminary analysis you do is to run the PhageTerm tool (use this tool link if you are TAMU internal user) to generate a report that suggests the type of genome ends.
- Choose the input files based on which dataset gave the contig for the phage genome. For the FASTQ mandatory input use the better set (usually R1). For the optional input, use the other dataset (usually R2).
- Name the output file with the phage name.
- Execute.
- When complete, open the output called report.
More Information
- After the raw contig is assembled, the end sequences of the contig need to be verified and completed by PCR. This is a process called genome closure. A protocol for genome closure is here.
Congratulations on successfully completing this tutorial!
Help us improve this content!
Please take a moment to fill in the Galaxy Training Network Feedback Form. Your feedback helps us improve this tutorial and will be considered in future revisions.